The PRM module specifies attributes, entities, relationships and dependencies. The information in the PRM is very interlinked since different methods have to access the same data from different starting points. e.g. access all the attributes from a given entity is easier from that specific entity instance via entity.attributes, whereas when iterating over all attributes in the prm it is easier to do using prm.attributes. Naturally all attributes, entities, relationships, dependencies are instanciated only once and then referenced. The method xml_prm.parser.parsePRM() is initializing all instance variables.
Path to a compatible datainterface xml specifiaction
Dictionary of all Dependency instances
Name of the Probabilistic Relational Model
Dictionary of all Relationship instances
List of attributes that are topologically sorted using prm.attribute.topologicalSort()
All attributes need to implement the class Attribute that defines a set of methods that need to implemented. Currently ProbReM supports a set of discrete variables, some attribute types are not probablistic and serve another purpose, e.g. as a foreign key.
All attributes are instantiated by calling the attributeFactory().
digraph inheritance26a2f3948e { rankdir=LR; size="8.0, 12.0"; "prm.attribute.ExistAttribute" [style="setlinewidth(0.5)",URL="#prm.attribute.ExistAttribute",fontname=Vera Sans, DejaVu Sans, Liberation Sans, Arial, Helvetica, sans,height=0.25,shape=box,fontsize=10]; "prm.attribute.Attribute" -> "prm.attribute.ExistAttribute" [arrowsize=0.5,style="setlinewidth(0.5)"]; "prm.attribute.Attribute" [style="setlinewidth(0.5)",URL="#prm.attribute.Attribute",fontname=Vera Sans, DejaVu Sans, Liberation Sans, Arial, Helvetica, sans,height=0.25,shape=box,fontsize=10]; "prm.attribute.NotProbabilisticAttribute" [style="setlinewidth(0.5)",URL="#prm.attribute.NotProbabilisticAttribute",fontname=Vera Sans, DejaVu Sans, Liberation Sans, Arial, Helvetica, sans,height=0.25,shape=box,fontsize=10]; "prm.attribute.Attribute" -> "prm.attribute.NotProbabilisticAttribute" [arrowsize=0.5,style="setlinewidth(0.5)"]; "prm.attribute.BinaryAttribute" [style="setlinewidth(0.5)",URL="#prm.attribute.BinaryAttribute",fontname=Vera Sans, DejaVu Sans, Liberation Sans, Arial, Helvetica, sans,height=0.25,shape=box,fontsize=10]; "prm.attribute.Attribute" -> "prm.attribute.BinaryAttribute" [arrowsize=0.5,style="setlinewidth(0.5)"]; "prm.attribute.IntegerAttribute" [style="setlinewidth(0.5)",URL="#prm.attribute.IntegerAttribute",fontname=Vera Sans, DejaVu Sans, Liberation Sans, Arial, Helvetica, sans,height=0.25,shape=box,fontsize=10]; "prm.attribute.Attribute" -> "prm.attribute.IntegerAttribute" [arrowsize=0.5,style="setlinewidth(0.5)"]; "prm.attribute.EnumeratedAttribute" [style="setlinewidth(0.5)",URL="#prm.attribute.EnumeratedAttribute",fontname=Vera Sans, DejaVu Sans, Liberation Sans, Arial, Helvetica, sans,height=0.25,shape=box,fontsize=10]; "prm.attribute.Attribute" -> "prm.attribute.EnumeratedAttribute" [arrowsize=0.5,style="setlinewidth(0.5)"]; "prm.attribute.ForeignAttribute" [style="setlinewidth(0.5)",URL="#prm.attribute.ForeignAttribute",fontname=Vera Sans, DejaVu Sans, Liberation Sans, Arial, Helvetica, sans,height=0.25,shape=box,fontsize=10]; "prm.attribute.Attribute" -> "prm.attribute.ForeignAttribute" [arrowsize=0.5,style="setlinewidth(0.5)"]; }
An ‘abstract’ class that defines an attribute (variable) of an entity or relationship class.
The Conditional Probability Distribution of an attribute of type :class:’.CPD’
Every attribute has a unique identifier that can be used when hashing. At this point the fullname is used. We could also think of some numerical value derived form the name for performance.
The cardinality is the size of the domain. This value has to be assigned by the specific attribute class which is being instantiated.
A list of the Dependency instances that the given attribute is a child of
A list of the Dependency that the given attribute is a parent of
The domain is a list of all possible values the attribute can take. This value has to be assigned by the specific attribute class which is being instantiated.
Every attribute is attached to an entity or relationship class. erClass = Entity or Relationship Object
The full name an attribute is either ‘Entity_name.Attribute_name’ or ‘Relationship_name.Attribute_name’
Boolean. If True then there is not a corresponding data field (latent variable)
The dictionary indexing serves to access the index of the domain values. indexing stores { key= domain value : value= index of domain value}.
Returns the index of the domain list given an attribute value. This is a function because different attribute classes can compute this index differently.
| Parameters: | value – Value that is in the domain |
|---|
The name of the attribute has to be unique among the attributes of the same class, e.g. two attributes in different entities could have the same name.
A Binary Attribute can only take on two different values
A Enumerated Attribute can take values stored in domain. Note that there are no constraints on what is passed in attrValues. In case of working with strings, the performance will be lower because a lot of string operations will have to be executed.
Size of domain
List of domain values
An Exist Attribute is a binary variable used when making inference in uncertain relationships. Reference Uncertainty implies that we don’t know which objects of two associated entities are connected through the relationship. Thus we assume a full relationship, meaning that there is an object for every possible combination of entity objects. If the exist attribute of a relationship oject is 1, then the object is considered to be present in the data. Relationship are usually sparse, e.g. only few connections exist. There is no need to store all possible connections, not in the data nor in the model. The relationship type is usually even more restricted (e.g. 1:n), allowing for a efficient representation.
An Foreign Attribute figures as part of the primary key of a relationship class. The foreign attribute points to the primary key of an entity class which is stored in target.
The CPD is shared with the target attribute. As the target is often the primary key, the CPD would be None.
Overwritten from class Attribute. The full name a foreign attribute is ‘Relationship_name.Target_name’.
The target is an attribute of an entity class that the relationship class the forgein attribute is part of. Often this is the primary key.
A Integer Attribute can take values in a certain interval
Size of domain
List of integer values
An Attribute that is not probabilistic, which means that it will not have a local distribution and that it can’t be part of any probabilistic dependency. It is required for slotchains that use the non probabilistic primary keys.
Returns an instance of the attribute of type type.
Returns a list of attributes that are lexically sorted. A topological sort or topological ordering of a directed acyclic graph (DAG) is a linear ordering of its nodes in which each node comes before all nodes to which it has outbound edges. Every DAG has one or more topological sort <http://en.wikipedia.org/wiki/Topological_sorting>.
This abstract class serves as a container for the objects that contain attributes. These objects are either Entity classes or Relationship classes; each can contain Attribute classes which themselves have to know which container object they belong to. The Entity/Relationship classes inherit the ERClass class. Therefore, an attribute can find the type of its container object by calling self.erClass.type()

Represents an entity class in the relational schema.
List that contains the Attributes references of the entity class
Unique name
The primary key is a list of Attribute objects of the entity. The pk is created automatically as a NotProbabilisticAttribute if not specified otherwise. It is stored as a list with just one item.
String representation of primary key
List that contains the Relationship references that are connected to the entity.
An relationship class relates two entity classes ( implicitly using their primary keys as identifiers). Note the source of confusion, Relationship refers to the Entity-Relationship model; not to be confused with the probabilistic Dependency which is conceptually also a relationship
A dictionary that contains the attributes references of the relationship class {key : Attribute name, value: Attribute}
List of Entities connected to the relationship
Dictionary represenation of self.pk where the key is an entity and the value a list of foreign attributes that belong to that entity, e.g. {key= Entity : value=[ ForeignAttribute , .. ]}
Unique name
The primary key of a relationship class is usually specified by the set of foreign keys of connected entities. A relationship class has a primary key that consists of a list of ForeignAttribute instances whose target‘s are attributes of the connecting entities (usually their primary key attributes).
List of string representation of self.pk
Reference uncertainty introduces uncertainty about the structure of the data itself, e.g. the entries of a relationship table of an ER diagram, and thus the state space of the Markov Chain increases considerably. We associate a binary exist variable with every possible entry in uncertain relationship tables. As the number of exist’ attributes grows exponentially with the size of the tables, inference becomes intractable. We avoid the explosion of the state space by introducing a `constraint attribute that enforces certain structural properties, e.g. a 1:n relationship. However, this results in complex probabilistic dependencies among the exist objects. A more involved Metropolis-Hastings algorithm is required that samples exist objects using an appropriate proposal distribution. A proposal is an assignment to all exist objects associated with one constraint object, which allows us to introduce probabilistic dependencies that would not be allowed in a traditional PRM.
The exist attribute of type ExistAttribute.
The value uncertain is the fixed-parameter ntoK in the k in the n:k relationship type. This parameter serves as a fixed-parameter tractability approach, for more information see the documentation.
Reference to the Enitity that is on the k-side of the relationship
Reference to the Enitity that is on the n-side of the relationship
A dependency represents a probabilistic dependency between two Attribute classes, the child and the parent attribute.
Aggregation is necessary when a dependency is of type 1:n or m:n as there will be multiple
parent objects mapping to a child object’s CPD that has only one parameter for this parent attribute.
Aggregation can be any function 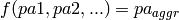 , see data.aggregation
, see data.aggregation
The SlotChain is computed via a depth first search algorithm. As there can’t be loops in the relational schema, we can return the first path that we encounter.
Note that when the model doesn’t load, it is usually because of the infinite loop that only quits when a slot chain was found. So far that always resulted from an error in the specification and not in the code...
Another disadvantage is that there could be multiple paths in the same schema. In fact you could define a different dependency for each different path. This method uses the first path that is found as the slotchain.
If a constraint has been defined in the specification, e.g. in the following form:
self.constraint = "...,e1.a1=r1.a2,r1.a3,e2.a4,..."
where e1, e2 are of type Entity, r1 of type Relationship and a1, a2, a3, a4 are of type Attribute. From this string slotchain, slotchain_string and slotchain_attr_string can be extracted. In case no constraint has been specified, computeSlotChain() is called to compute a traditional slotchain.
| Parameters: | attributes – All Attribute instances in the model |
|---|
The constraint of a dependency defines how the attribute objects in the relational skeleton are connected. Introduced by Heckerman et al. in the DAPER model, the concept of a constraint is a generalized version of the slotchain introduced by Getoor et al.
Unique name of the dependency
Even though the probabilistic dependency uses the constraint when specifying a PRM model, often the constraint results in the traditional slotchain, the ‘path’ through the relational schema that links the parent and child attribute via a list of entities and relationships, connected by foreign keys. The elements in the list slotchain are interchangeably [..., Entity, Relationship, Entity,... ]
List of the string represenation of the attributes that define the slotchain, e.g. Professor.professor_id=advisor.professor_id
Special Dictionary representation of the slotchain. The key is an Entity, and the value is basically self.slotchain_attr_string without all entries that contain the key entity {key = ERClass : value = list of string constraints }.
List containing the string representation (e.g. Professor, advisor) of the slotchain entities/relationships
Reference uncertainty introduces uncertainty about the structure of the data itself, e.g. the entries of a relationship table of an ER diagram, and thus the state space of the Markov Chain increases considerably. We associate a binary exist variable with every possible entry in uncertain relationship tables. As the number of exist’ attributes grows exponentially with the size of the tables, inference becomes intractable. We avoid the explosion of the state space by introducing a `constraint attribute that enforces certain structural properties, e.g. a 1:n relationship. However, this results in complex probabilistic dependencies among the exist objects. A more involved Metropolis-Hastings algorithm is required that samples exist objects using an appropriate proposal distribution. A proposal is an assignment to all exist objects associated with one constraint object, which allows us to introduce probabilistic dependencies that would not be allowed in a traditional PRM.
Reference to the Attribute, i.e. a foreign key in an entity instance, that is on the k-side of the relationship. It is either the parent or the child.
Reference to the Attribute, i.e. a foreign key in an entity instance, that is on the n-side of the relationship. It is either the parent or the child.
Is True if self.nAttribute and self.parent refer to the same attribute instance
If uncertainRelationship is True, then uncertainRelationship will point to the uncertain relationship UncertainRelationship
The model parameters in a ProbReM project are the conditional probability distributions (CPDs) defined for each probabilistic attribute defined in the model. They are also refered to as local distributions interchangeably.

A conditional probability distribution CPD is defined for an attribute. This is an abstract version of a CPD that defines a set of methods all CPD implementations must provide.
| Parameters: | fullAssignment – List of values order such that [attributeValue,ParentValue1,ParentValue2,....] |
|---|---|
| Returns: | Loglikelihood of fullAssignment |
The tabular representation of a CPD for discrete variables. A matrix of dimensions m x n, where
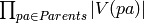
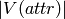
This matrix grows exponentially with the number of parents, thus not suited for large V-Structures.
Calculates the cumulative distribution of the tabular CPD by incrementally summing the columns
Calculates the log probability distribution cpdLogMatrix and cumulative log probability distribution cumLogMatrix
Returns the conditional probability distribution of the gbnV given its parent values.
| Parameters: | gbnV – GBN instance |
|---|---|
| Returns: | A 1 x |attr.domain| numpy.array probability distribution |
Log values of cpdMatrix
The CPD matrix of type numpy.array. The rows represent different parent assignments, the columns of a row define the distribution over the attribute.
Dimension of cpdMatrix
Log values of cumMatrix
Cumulativ cpdMatrix. Computed by computeCumulativeDist()
See indexingCPD()
See indexingCPD()
Returns the row and column indices for a full assignment to the attribute attr. indexRow is the index of the row of the cpd matrix that corresponds to the assignment of the parent attributes. The parents attribute values are ordered the same way as in attr.parents. indexColumn is the index of the column that corresponds to the assignment of the attribute value itself.
| Parameters: | currentRow – List containing a full assignment, [attributeValue,`parentValue1`,`parentValue2`,....] |
|---|---|
| Returns: | Tuple [indexRow,`indexColumn`] |
Computes the number of possible parent assigments and the index multipliers needed to compute the row index of a given parent assignment, see indexingCPD().
| Parameters: | fullAssignment – List of values order such that [attributeValue,`parentValue1`,`parentValue2`,....] |
|---|---|
| Returns: | Loglikelihood of fullAssignment using cpdLogMatrix |
Computes the parent assignment given an row index of cpdMatrix
| Parameters: | index – Row index of cpdMatrix |
|---|---|
| Returns: | Parent assignment associated with index |
