

Next: Regularization by Convolution
Up: Kernel Density Estimation: Parzen
Previous: Kernel Density Estimation: Parzen
Figure 4:
Product Kernel Window Functions: instead of counting the number of random samples within a hypercube centered at 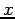 , we can associate a single-variate kernel function with each dimension and weight the count for each random sample by the product of its kernelized distances from in each dimension. More generally a multi-variate kernel function may be used.
, we can associate a single-variate kernel function with each dimension and weight the count for each random sample by the product of its kernelized distances from in each dimension. More generally a multi-variate kernel function may be used.
|
|
Instead of simply counting the number of random samples that fall within a fixed volume surronding , we can weight the count [DHS01] for each random sample by its kernelised distance from . This can be achieved by replacing the unit hypercube window function  with a smooth, symmetric kernel density function
with a smooth, symmetric kernel density function 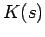 satisfying
satisfying
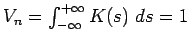 and
and
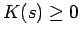 and then rewriting 7 as:
and then rewriting 7 as:
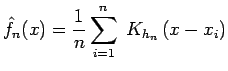 |
(8) |
where the bandwidth 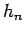 is shifted into the definition of the kernel as the standard-deviation so that
is shifted into the definition of the kernel as the standard-deviation so that
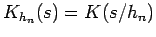 and the term involving the volume disappears since
and the term involving the volume disappears since 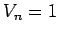 . The gaussian kernel is most often used;
. The gaussian kernel is most often used;
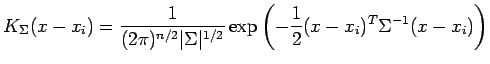 |
(9) |
where 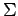 is the covariance or bandwidth matrix. The key difference between the parametric density estimate 1 and non-parametric kernel density estimation 8 is that in the former the models that define the mixture have means or centers that are estimated from the data, while the latter makes use of kernel functions that are centered at the various samples in the training data.
is the covariance or bandwidth matrix. The key difference between the parametric density estimate 1 and non-parametric kernel density estimation 8 is that in the former the models that define the mixture have means or centers that are estimated from the data, while the latter makes use of kernel functions that are centered at the various samples in the training data.
The use of kernel basis functions has several advantages, the most significant of which is that the resulting estimate
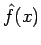 is also a smooth density function. It has been shown [Fuk72] that provided that
is also a smooth density function. It has been shown [Fuk72] that provided that
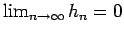 and
and
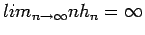 the estimated kernel density estimate pointwise converges in probability to the true density - this is asymptotic consistency; uniform convergence in probability is also proved under the additional condition
the estimated kernel density estimate pointwise converges in probability to the true density - this is asymptotic consistency; uniform convergence in probability is also proved under the additional condition
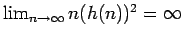 .
.
Figure 5:
Comparing the Gaussian and Epanetchnikov Kernels [Ihl03]: a bandwidth of 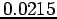 is used - the entropy for the Gaussian and Epanetchnikov Kernels are
is used - the entropy for the Gaussian and Epanetchnikov Kernels are 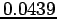 and
and 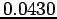 respectively. Notice how even though the original or true density is defined only on the interval
respectively. Notice how even though the original or true density is defined only on the interval ![$ [0,1]$](img18.png) so that random samples are also only generated on this interval, the resulting estimated density extends outside this interval; this can be good if there are regions of missing values so that an implicit non-linear interpolation estimates the density in these regions; it can be bad when the estimation extends into regions for which the density is meant to be undefined.
so that random samples are also only generated on this interval, the resulting estimated density extends outside this interval; this can be good if there are regions of missing values so that an implicit non-linear interpolation estimates the density in these regions; it can be bad when the estimation extends into regions for which the density is meant to be undefined.
|
|
Next: Regularization by Convolution
Up: Kernel Density Estimation: Parzen
Previous: Kernel Density Estimation: Parzen
Rohan Shiloh SHAH
2006-12-12
![\includegraphics[scale=0.75]{image_gaussian_window_function.eps}](img103.png)
![\includegraphics[scale=0.65]{image_kernel_density_comparison.eps}](img115.png)