
I'm currently a Member of Technical Staff at OpenAI in San Francisco, where I do research with the safety team. I am also a Ph.D. student in Computer Science at McGill University, supervised by Joelle Pineau. In the past, I worked on multi-agent reinforcement learning, emergent communication, deep learning methods for dialogue systems, and improving dialogue evaluation metrics.
I'm working on a project to increase honesty and transparency in talking about machine learning research, and to generally improve the health of the field. It's called Retrospectives. Curious parties can check out the website to learn more or see our NeurIPS 2019 workshop.
News
- The Retrospectives workshop at NeurIPS 2019 was a huge success! You can find the videos here.
- Our paper on bridging the gap from emergent communication to natural language was accepted to ICLR 2020.
Selected publications
You can view my full up-to-date list of publications here.
Ryan Lowe*, Abhinav Gupta*, Jakob Foerster, Douwe Kiela, Joelle Pineau.
"On the Interaction Between Supervision and Self-Play in Emergent Communication"
In International Conference on Learning Representations (ICLR), 2020.
[paper]
Ryan Lowe, Jakob Foerster, Y-Lan Boureau, Joelle Pineau, Yann Dauphin.
"On the Pitfalls of Measuring Emergent Communication"
In International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS), 2019.
[paper] [code]
Ryan Lowe*, Yi Wu*, Aviv Tamar, Jean Harb, Pieter Abbeel, Igor Mordatch.
"Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments."
In Neural Information Processing Systems (NeurIPS), 2017.
[paper] [code]
Ryan Lowe*, Michael Noseworthy*, Iulian Serban, Nicholas Angelard-Gontier, Yoshua Bengio, Joelle Pineau.
"Towards an Automatic Turing Test: Learning to Evaluate Dialogue Responses."
In Association for Computational Linguistics (ACL), 2017. [Outstanding Paper]
[paper] [code][retrospective]
Chia-Wei Liu*, Ryan Lowe*, Iulian Serban*, Mike Noseworthy*, Laurent Charlin, Joelle Pineau.
"How NOT to Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation."
In Empirical Methods in Natural Language Processing (EMNLP), 2016. [Oral]
[paper]
Ryan Lowe*, Nissan Pow*, Iulian Serban, Joelle Pineau.
"The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems."
In SIGDIAL, 2015 [Oral].
[paper]
[code]
[dataset]
[slides]
Resources
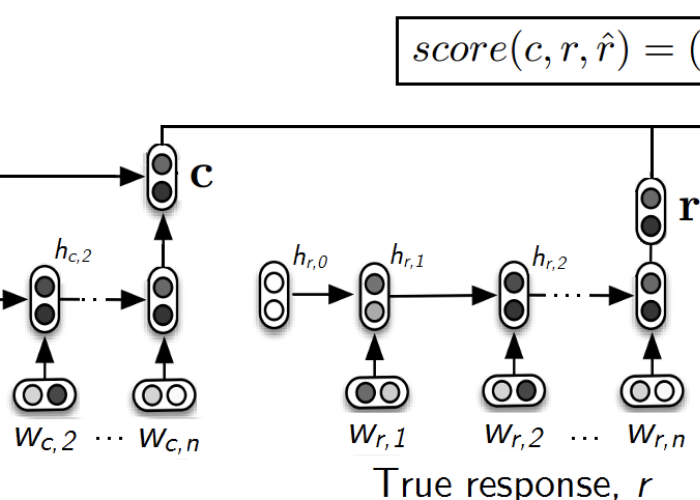
ADEM: An Automatic Dialogue Evaluation Tool
Most automatic evaluation methods for non-task-oriented dialogue (i.e. no task completion signal) perform poorly. We set out to train a model that could replicate human judgements of dialogue response quality on the Twitter dataset. We've open-sourced our model so that other researchers can use it: you can find the code here. While I don't currently recommend using ADEM to evaluate dialogue systems (I talk about some of the limitations of the model in a retrospective here), I suspect our methods could be improved upon and scaled up to achieve better performance.
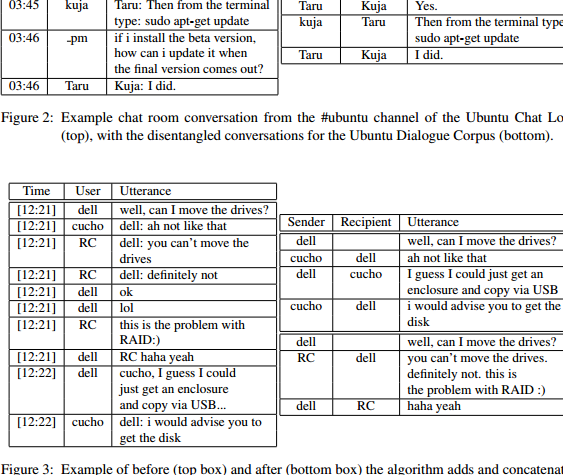
The Ubuntu Dialogue Corpus v2
The Ubuntu Dialogue Corpus v2 is an updated version of the original Ubuntu Dialogue Corpus. It was created in conjunction with Rudolph Kadlec and Martin Schmid at IBM Watson in Prague. The updated version has the training, validation, and test sets split disjointly by time, which more closely models real-world applications. It has a new context sampling scheme to favour longer contexts, a more reproducible entity replacement procedure, and some bug fixes.
You can download the Ubuntu Dialogue Corpus v2
here.
Code to replicate the results from the paper is available
here.

The Ubuntu Dialogue Corpus v1
The Ubuntu Dialogue Corpus v1 is a dataset consisting of almost 1 million dialogues extracted from the Ubuntu IRC chat logs. This dataset has several desirable properties: it is very large, each conversation has multiple turns (a minimum of 3), and it is formed from chat-style messages (as opposed to tweets). There is also a very natural application towards technical support. The size of this dataset makes it a great resource for training dialogue models, particularly neural architectures.
Note that this dataset is outdated; please use the Ubuntu Dialogue Corpus v2 .