With the tremendous growth in data science and machine learning, it is becoming increasingly clear that traditional relational database management systems (RDBMS) are lacking appropriate support for the programming paradigms required by such applications, whose developers prefer tools and packages that perform the computation outside the database system.
The most common current approach to develop machine learning and data science applications is to use one of the many statistical languages such as R , MATLAB, Octave , etc., or packages such as pandas , NumPy , theano , etc., meant to augment a general purpose language like Python with linear algebra support. Should the data to be used reside in an RDBMS, the first step in these programs is to retrieve the data from the RDBMS and store them in user space. From there, all computation is done at the user end. Alternatively, sometimes users manually export the required data from the database into files that are then fed into such applications. Needless to say, user systems do not posses massive amount of processing power unlike servers running an RDBMS, often forcing them to work with a smaller subset of data. Users might also choose smaller data sets as transfer costs and latencies to retrieve the data from the database system can be huge. This data subsetting can be counterproductive, as it has been pointed out that having a larger data set can reduce the complexity of the algorithm that needs to be built , while also providing better accuracy. Additionally, once the data is taken out of the RDBMS, all further data selection and filtering need to be performed within the statistical package. Especially in the feature engineering phase of a learning problem, where such relational operators are needed . Therefore, the statistical community has augmented their favorite systems with some relational functionality, such as the pandas DataFrame designed to work on top of NumPy for Python and the DataFrame objects in R. However such implementations are not as sophisticated as the capabilities of a conventional RDBMS when it comes to executing relational operations.
Attempts by database community to support linear algebra operations by supporting UDFs written in host languages such as Python, R, etc. as well as related attempts in supporting linear algebra by extending SQL has failed to make inroads among data scientists. This is primarily due to the fact that these approaches are more tedious in the usability aspect and therefore hamper the productivity of the user.The goal behind AIDA is to support in-database analytics without sacrificing usability.
Developed in Python, AIDA allows data scientists to use regular Python intepreters as clients to connect to the database and perform linear algebra using familiar syntax of NumPy/pandas and relational operations using Object Relational Mapping (ORM) style API support.
This, for example, allows users to write code such as below, mixing both relational and linear algebra operators on the objects.
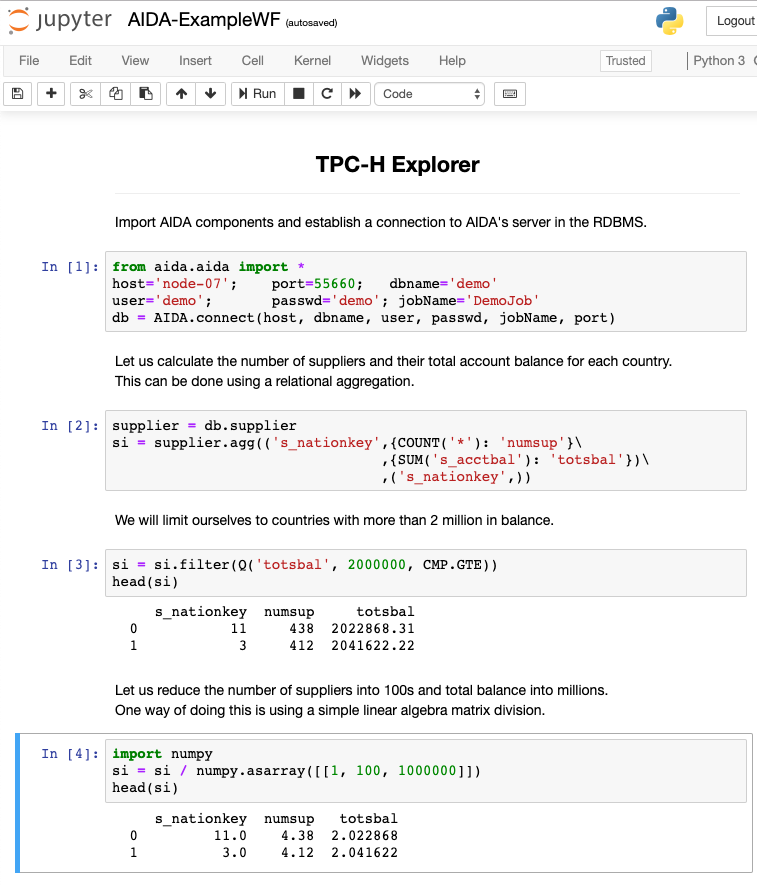
AIDA's client libraries can cleverly shift this computation to AIDA's server , that resides in the RDBMS.
This has two advantages.AIDA facilitates this by an RMI mechanism to move the computation to the actual objects on the server side.
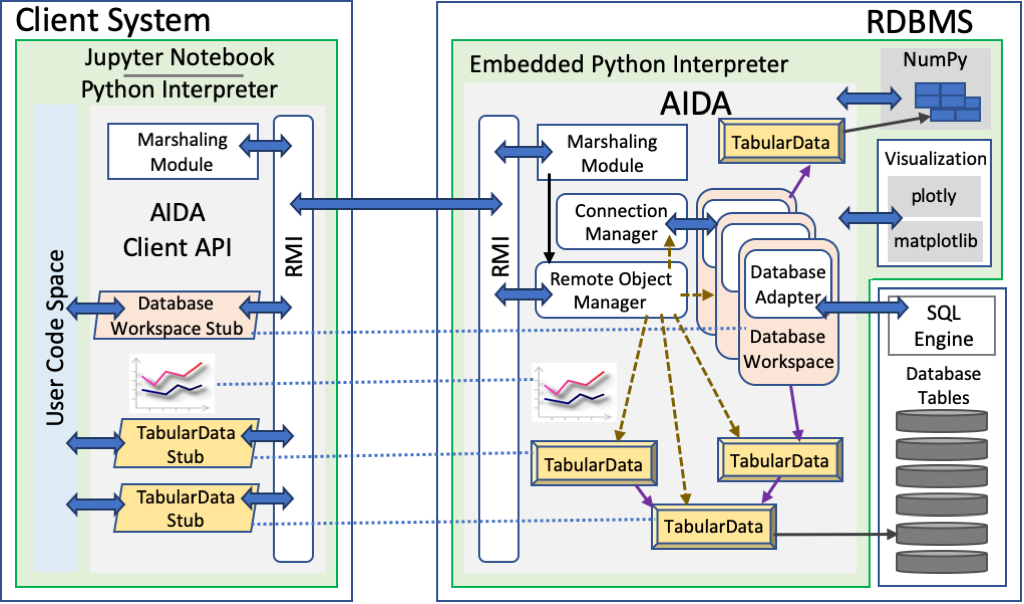
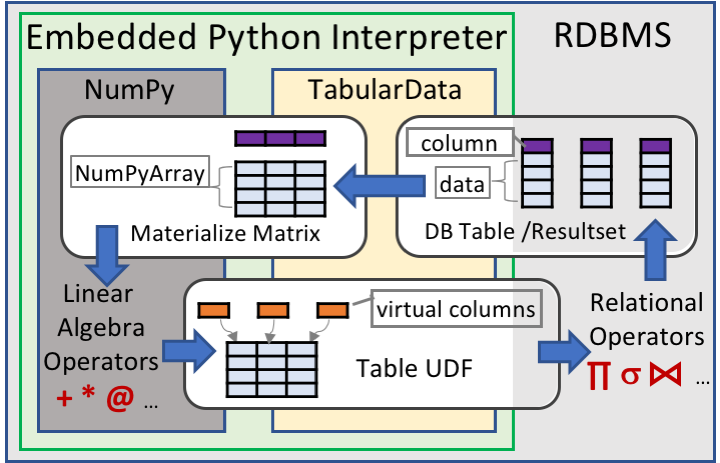
AIAD's server interally uses NumPy to do its linear algebra computations whereas it pushes down relational operations as SQL using Table UDFs into the RDBMS via a Database Adapter intended for that RDBMS. Therefore by building Database Adapters for different RDBMS, we can easily port AIDA to that RDBMS. The current implementation of AIDA works on MonetDB.
Depending on the nature of operations requested, AIDA can move data transparently between the RDBMS and NumPy using its TabularData abstraction. This ensures that the users do not have to worry about the data set's internal format. AIDA takes care of this nuance and does any transformations required. AIDA's server is also clever in some optimizations , in that it does lazy evaluations of relational operations (therefore reducing the overall computations required) and avoids unnecessary format transformations between NumPy and RDBMS.
AIDA also provides support for in-databse visualization of data sets through matplotlib and plotly.