Current Projects:
 |
Advanced in-database Analytics
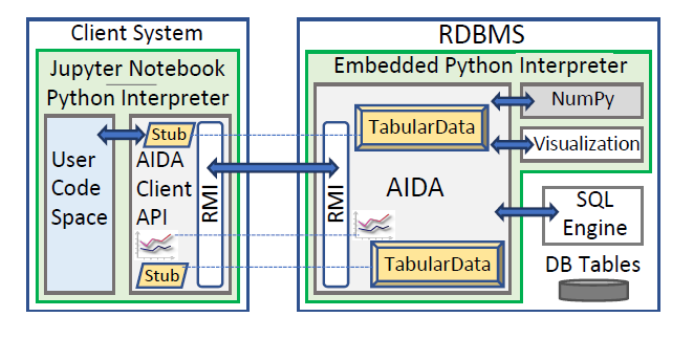
The AIDA project (Advanced in-database Analytics) tackles the problem of integrating advanced analytics with traditional database queries in a novel manner. AIDA emulates the syntax and semantics of popular Python statistical data science packages but transparently executes the required transformations and computations inside the relational database systems. In particular, AIDA works with a regular Python interpreter as a client to connect to the AIDA server which is embedded within the database system. The interface supports the seamless use of both classical database operators and linear algebra operations using a unified abstraction. AIDA relies on the database engine to efficiently execute the database operations and on an embedded Python interpreter to perform linear algebra operations. AIDA was originally designed to work within columnar data-stores. As both the Python interpreter and the database engine reside in the same execution environment, and both use columnar data structures, a unified ”TabularData” structure avoids data copy and transformation. But AIDA can also work with other database engine, and it fully functional with the row-based database system PostgreSQL. |
 |
Monitoring-as-a-Service in the Cloud
In this project we aim at developing a Monitoring-as-a-Service platform for monitoring distributed applications in the cloud. Given the complex dependencies in these systems, it is important to not only monitor the performance of the individual components but also how they interact and call each other. As such, our lab uses the message flows exchanged between components (i) to determine performance metrics such as response times and throughput, (ii) to determine how the components call each other in terms of call graphs, and (iii) to determine what kind of service each component provides. Our solution takes advantage of advances in software-defined network technology and virtual switches that allow us to observe message flows in a nonintrusive and flexible manner, and advances in machine learning, in particular deep learning, that allow us to determine service types without profound knowledge of the services themselves. |
Completed Projects:
|
Array-based Query Optimization
Over the last two decades the database community has developed column-based relational database system, that have shown excellent performance on complex SQL analytical queries. In these systems a column of a table is stored in contiguous space similar to an array. This motivated our HorsePower project to use array-based programming languages at the core of an efficient database engine. We proposed a low-level array programming language, called HorseIR, specifically designed to support relational operators, created translation tools that translate SQL queries into HorseIR programs, and built a compiler that compiles these programs to lower-level code using a wide range of array-based compiler optimization techniques. HorsePower also supports the embedding of ``user-defined'' functions, that are written in a high-level language such as Matlab, into SQL statements. HorsePower translates these functions into HorseIR programs, allowing for a unique holistic compiler-based optimization across traditional SQL and more complex analytics functions. |
 |
Cloud-based services for multiplayer games.
We look how base services of game engines such as data dissemination, replication management or interest management can be offered as cloud services. Our current interest focuses on scalable and elastic publish/subscribe services that are able to handle the high subscriptions and data dissemination rates of multiplayer games, and that can handle varying load on channels They should also help with interest management, that is, automatically determine the objects and players a player might be interested in. |
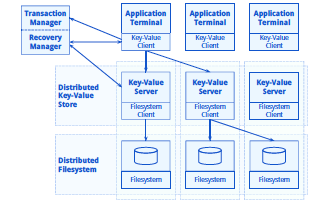 |
Supporting OLTP workloads in the cloud.
Originally part of the CumuloNimbo project, we look at aspects of transaction isolation, durability, and large-scale data management across a multi-layered and horizonally partitioned infrastructure. We extend the HBase tuple store to work holistically together with upper layers to provide snapshot isolation, and we propose a recovery infrastructure that can handle the failure of individual components in any of the infrastructure layers. Furthermore, as OLTP workloads create a lot of updates, triggering compactions in append-only data stores, we develop mechanisms to outsource compactions so that they do not negatively impact online processing. |
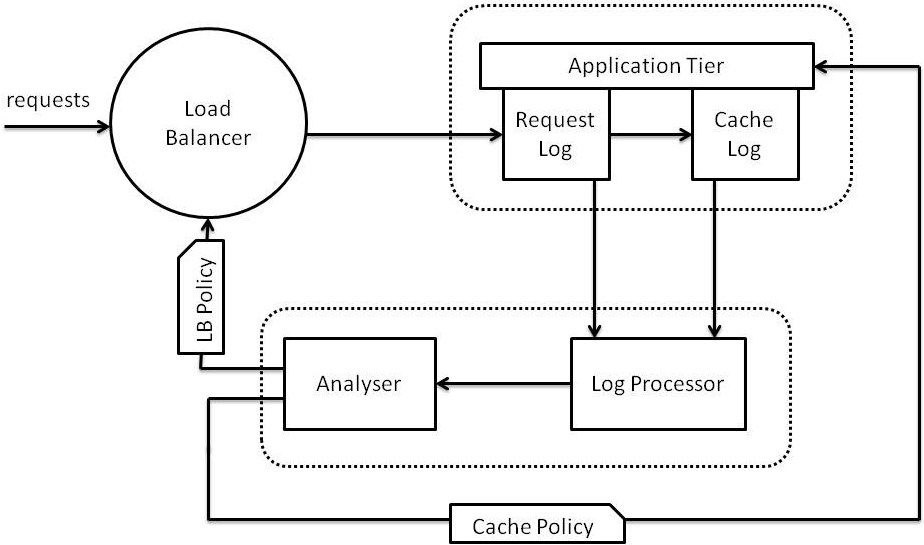 |
Large-scale cache management.
While large distributed caches allow the storage of business objects in main memory, they represent a further layer of indirection. Our approach aims in building a caching infrastructure that eliminateis indirection as much as possible. The idea is to collocate a cache layer with each application server instance and allocate both objects and requests to application servers in such a way that load is equally distributed and most accesses to objects are local. |
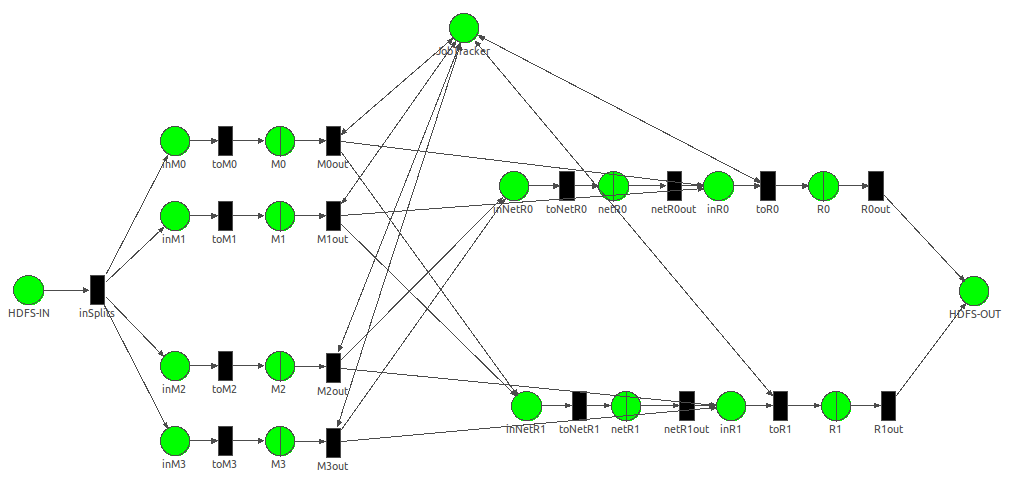 |
Understanding performance of large-scale data
processing.
Node configurations can have a significant impact on the execution time of large-scale computations. We aim at predicting the performance of various node configurations using queueing networks so that practioners can choose the configuration that performs best under their workload. |
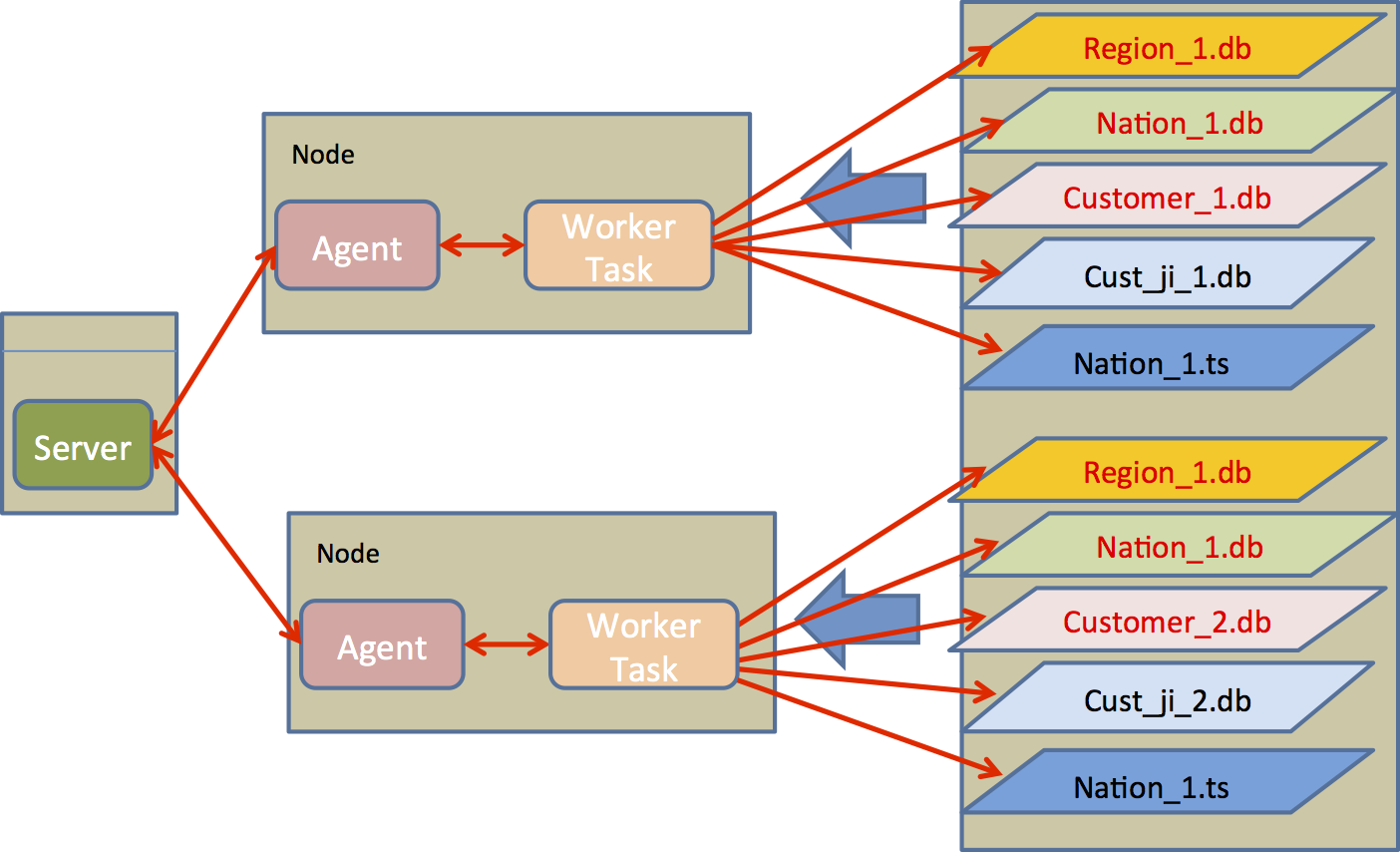 |
Index support for highly partitioned data.
We are looking for indexing schemes that are beneficial when data is highly partitioned (SQL or key/value stores). In particular, we look how partitioned main memory secondary indices in HBase can speed up queries on non-primary attributes. Furthermore, we propose join indices for partitioned column-stores. |
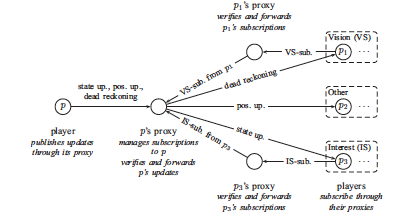 |
Scalable and secure peer-to-peer games
When fast-paced games are played in a peer-to-peer architecture or with mobile devices, cheating and scalability challenges are a major issue. In this project, we developed architectures and solutions that avoid and detect a wide range of cheats, are scalable to hundreds of players, and hide network latency so that such fast-paced games can even be played across wide area networks. |
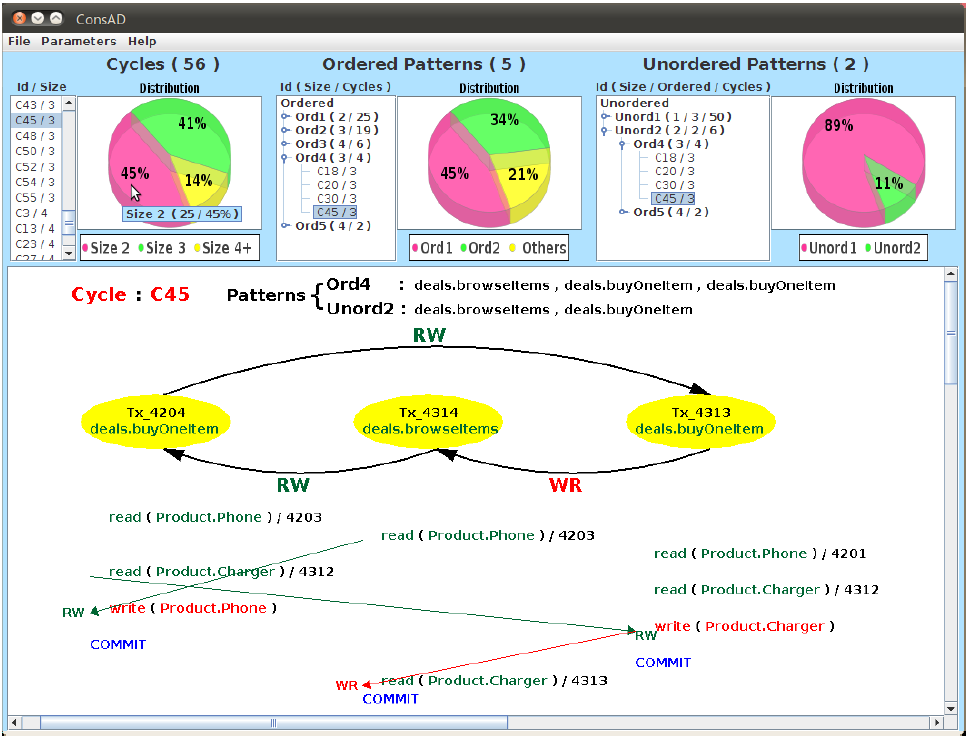 |
ConsAD: Determining the consistency level of transactional
applications on cloud data stores
In this project we developed ConsAD, a tool that detects and quantifies consistency anomalies for arbitrary multi-tier applications running under any isolation level. It can be used both with traditional relational database systems as well as distributed and replicated key/value stores. |